vizAPI
viz API 參考¶
-
probscale.viz.probplot(data, ax=None, plottype='prob', dist=None, probax='x', problabel=None, datascale='linear', datalabel=None, bestfit=False, return_best_fit_results=False, estimate_ci=False, ci_kws=None, pp_kws=None, scatter_kws=None, line_kws=None, **fgkwargs)[原始碼]¶ 機率、百分位數和分位數圖。
參數 data : 類陣列
要繪製的 1 維資料
ax : matplotlib 軸, 選用
要繪圖的軸。如果未提供,將建立新的軸。
plottype : 字串 (預設 = ‘prob’)
要建立的圖表類型。選項包括
- ‘prob’:機率圖
- ‘pp’:百分位數圖
- ‘qq’:分位數圖
dist : scipy 分佈, 選用
用於計算刻度位置的分佈。如果未指定,將使用標準常態分佈。
probax : 字串, 選用 (預設 = ‘x’)
將作為機率(或分位數)軸的軸(‘x’ 或 ‘y’)。
problabel, datalabel : 字串, 選用
分別為機率/分位數和資料軸提供的軸標籤。
datascale : 字串, 選用 (預設 = ‘log’)
另一個不是的軸的刻度
bestfit : bool, 選用 (預設為 False)
指定是否應在圖表中加入最佳擬合線。
return_best_fit_results : bool (預設為 False)
如果為 True,則會與圖表一起傳回結果字典。
estimate_ci : bool, 選用 (False)
使用百分位數自舉法估計並繪製最佳擬合線周圍的信賴區間。
ci_kws : dict, 選用
在計算最佳擬合線時,直接傳遞至
viz.fit_line的關鍵字引數字典。pp_kws : dict, 選用
在計算繪圖位置時,直接傳遞至
viz.plot_pos的關鍵字引數字典。scatter_kws, line_kws : dict, 選用
在繪製散佈點和最佳擬合線時,直接傳遞至
ax.plot的關鍵字引數字典。傳回值 fig : matplotlib.Figure
繪製圖表的圖形。
result : 線性擬合結果字典,選用
鍵值包括
- q : 分位數陣列
- x, y : 傳遞至函數的資料陣列
- xhat, yhat : 最佳擬合線中繪製的建模資料陣列
- res : 最佳擬合線的係數陣列。
其他參數 color : 字串, 選用
直接指定的 matplotlib 顏色引數,用於資料序列和最佳擬合線(如果已繪製)。此引數可供 seaborn 套件使用,不建議一般使用。相反地,應在
scatter_kws和line_kws中指定顏色。注意
使用者不應指定此參數。它僅供 seaborn 在
FacetGrid中操作時使用。label : 字串, 選用
資料序列的直接指定的圖例標籤。此引數可供 seaborn 套件使用,不建議一般使用。相反地,資料序列標籤應在
scatter_kws中指定。注意
使用者不應指定此參數。它僅供 seaborn 在
FacetGrid中操作時使用。另請參閱
viz.plot_pos,viz.fit_line,numpy.polyfit,scipy.stats.probplot,scipy.stats.mstats.plotting_positions範例
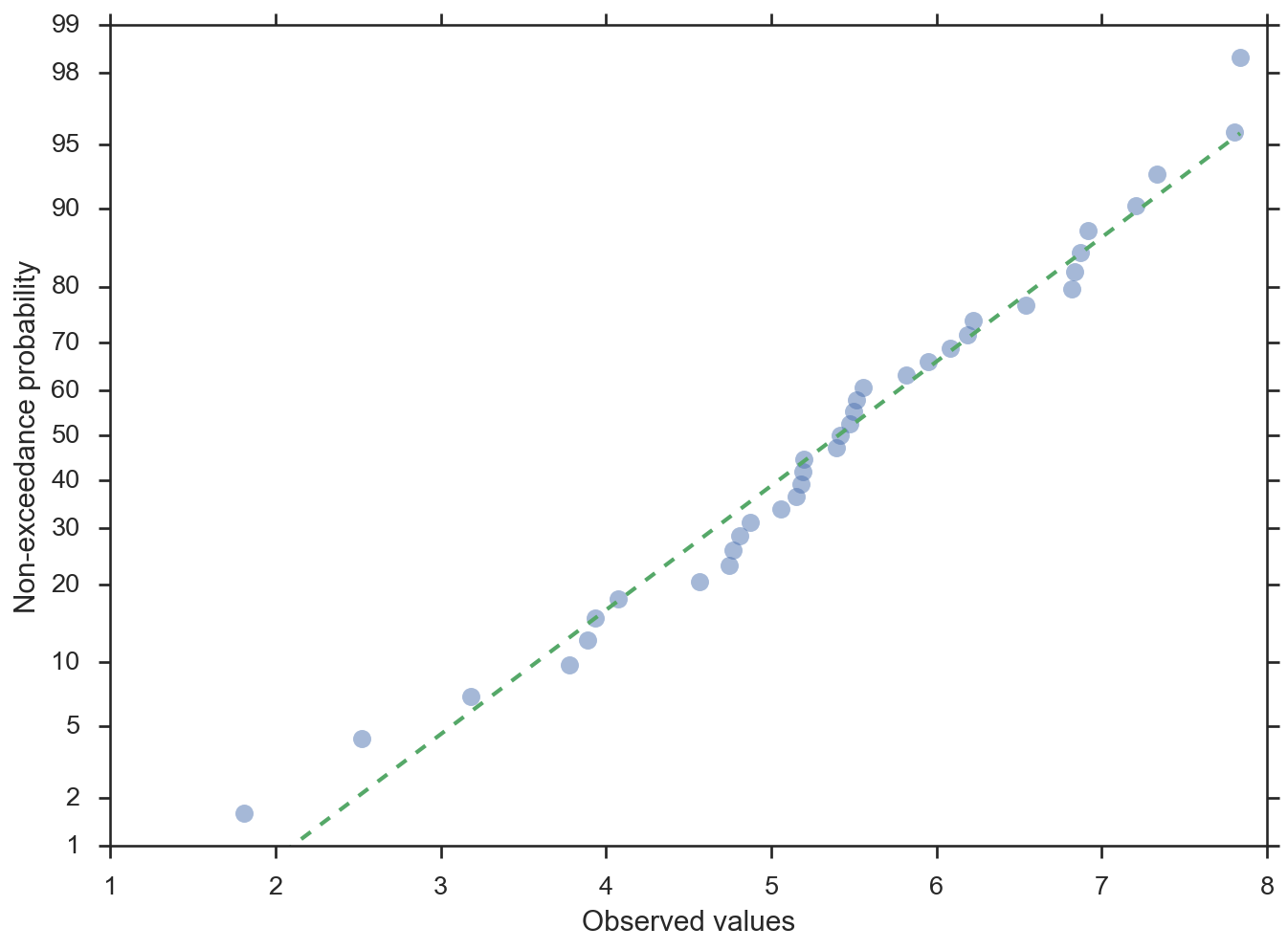
機率圖,機率位於 y 軸
>>> import numpy; numpy.random.seed(0) >>> from matplotlib import pyplot >>> from scipy import stats >>> from probscale.viz import probplot >>> data = numpy.random.normal(loc=5, scale=1.25, size=37) >>> fig = probplot(data, plottype='prob', probax='y', ... problabel='Non-exceedance probability', ... datalabel='Observed values', bestfit=True, ... line_kws=dict(linestyle='--', linewidth=2), ... scatter_kws=dict(marker='o', alpha=0.5))
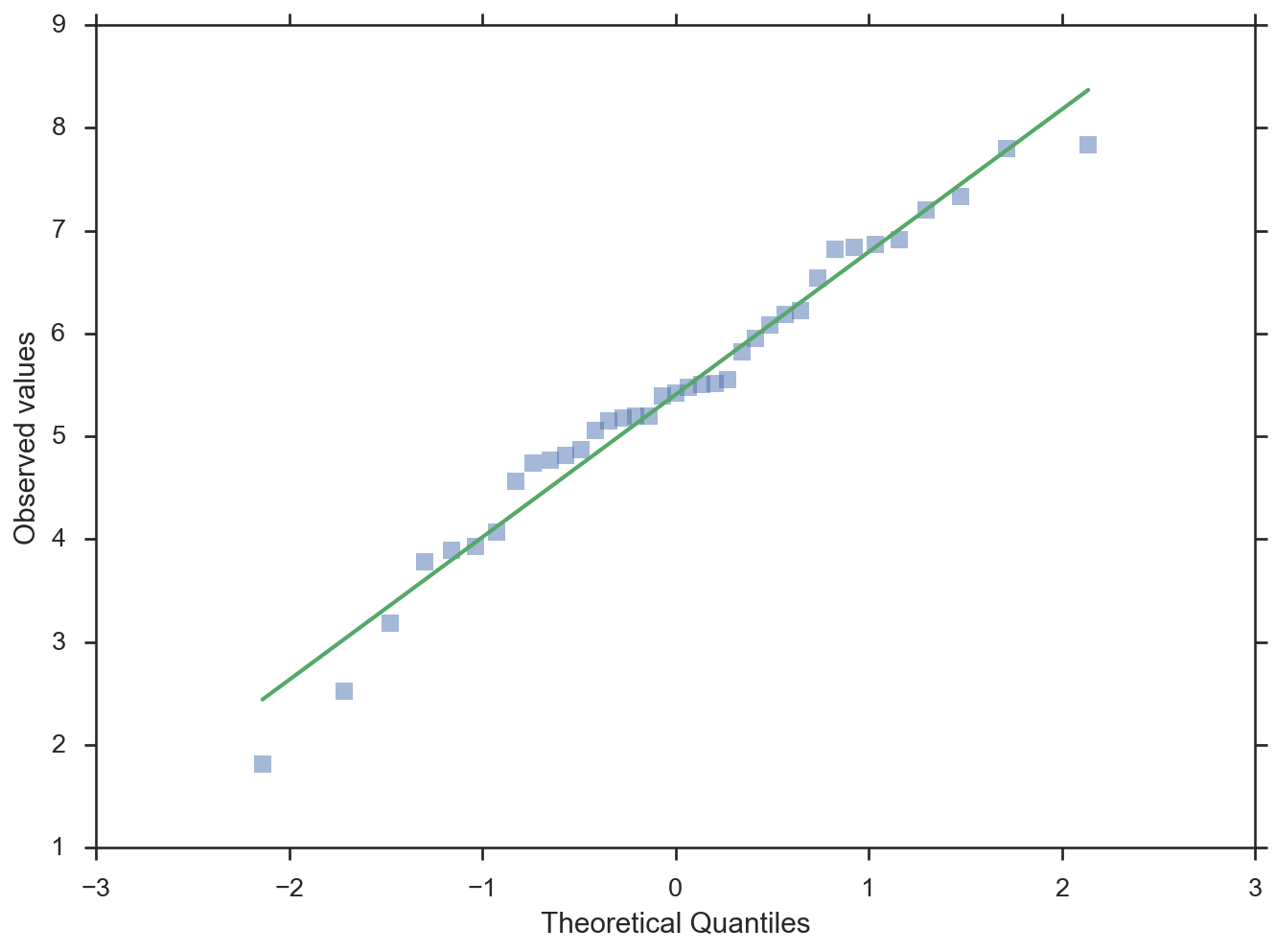
分位數圖,分位數位於 x 軸
>>> fig = probplot(data, plottype='qq', probax='x', ... problabel='Theoretical Quantiles', ... datalabel='Observed values', bestfit=True, ... line_kws=dict(linestyle='-', linewidth=2), ... scatter_kws=dict(marker='s', alpha=0.5))
-
probscale.viz.plot_pos(data, postype=None, alpha=None, beta=None)[原始碼]¶ 計算資料集的繪圖位置。大量借用
scipy.stats.mstats.plotting_positions。繪圖位置定義為:
(i-alpha)/(n+1-alpha-beta),其中i是排序n是資料集的大小alpha和beta是用於調整位置的參數。
可以明確設定
alpha和beta的值。也可以透過postype參數存取典型值。可用的postype值 (alpha, beta) 包括- 「類型 4」(alpha=0, beta=1)
- 經驗 CDF 的線性內插。
- 「類型 5」或「Hazen」(alpha=0.5, beta=0.5)
- 分段線性內插。
- 「類型 6」或「Weibull」(alpha=0, beta=0)
- Weibull 繪圖位置。所有分佈的無偏差超越機率。建議用於水文應用。
- 「類型 7」(alpha=1, beta=1)
- R 中的預設值。不建議與機率刻度一起使用,因為最小和最大資料點的繪圖位置分別為 0 和 1,因此無法顯示。
- 「類型 8」(alpha=1/3, beta=1/3)
- 近似中位數無偏差。
- 「類型 9」或「blom」(alpha=0.375, beta=0.375)
- 如果資料為常態分佈,則位置大致無偏差。
- 「中位數」(alpha=0.3175, beta=0.3175)
- 所有分佈的中位數超越機率(在
scipy.stats.probplot中使用)。 - 「apl」或「pwm」(alpha=0.35, beta=0.35)
- 與機率加權動量一起使用。
- 「cunnane」(alpha=0.4, beta=0.4)
- 常態分佈資料的近乎無偏差分位數。這是預設值。
- 「gringorten」(alpha=0.44, beta=0.44)
- 用於 Gumble 分佈。
參數 data : 類陣列
需要計算其繪圖位置的值。
postype : 字串, 選用 (預設:「cunnane」)
alpha, beta : float, 選用
如果透過 postype 參數可用的選項不足,則可以使用自訂繪圖位置參數。
傳回值 plot_pos : numpy.array
計算出的繪圖位置,已排序。
data_sorted : numpy.array
原始資料值,已排序。
參考文獻
http://artax.karlin.mff.cuni.cz/r-help/library/lmomco/html/pp.html http://astrostatistics.psu.edu/su07/R/html/stats/html/quantile.html https://scipy-docs.dev.org.tw/doc/scipy-0.17.0/reference/generated/scipy.stats.probplot.html https://scipy-docs.dev.org.tw/doc/scipy-0.17.0/reference/generated/scipy.stats.mstats.plotting_positions.html
-
probscale.viz.fit_line(x, y, xhat=None, fitprobs=None, fitlogs=None, dist=None, estimate_ci=False, niter=10000, alpha=0.05)[原始碼]¶ 將線擬合到各種形式(線性、對數、機率刻度)的 x-y 資料。
參數 x, y : 類陣列
分別為自變數和因變數資料。
xhat : 類陣列,選用
應估計
yhat的值。如果未提供,則會退回到x的已排序值。fitprobs, fitlogs : str, 選用。
定義應如何轉換資料。有效值為 ‘x’、‘y’ 或 ‘both’。如果使用
fitprobs,則變數應表示為百分比,例如,對於機率轉換,資料將使用lambda x: dist.ppf(x / 100.)轉換。對於對數轉換,lambda x: numpy.log(x)。請注意,不要將相同的值傳遞給fitlogs和figprobs,因為將會同時套用這兩種轉換。dist : 分佈, 選用
完全指定的 scipy.stats 類分佈物件,這樣可以呼叫
dist.ppf和dist.cdf。如果未提供,則預設為scipt.stats.norm的最小實作。estimate_ci : bool, 選用 (False)
使用百分位數自舉法估計並繪製最佳擬合線周圍的信賴區間。
niter : int, 選用 (預設 = 10000)
如果提供
estimate_ci,則為自舉法迭代次數。alpha : float, 選用 (預設 = 0.05)
自舉法估計的信賴水準。
傳回值 xhat, yhat : numpy 陣列
x和y的線性模型估計。results : dict
線性擬合結果的字典。鍵值包括
- 斜率
- 截距
- yhat_lo (估計 y 值的較低信賴區間)
- yhat_hi (估計 y 值的較高信賴區間)